无名摄影锐评NeurIPS 2025
各位观众朋友大家好,我是从来不带节奏,但节奏总来找我的凉月。欢迎收看鸽了不知道多久,但终于没在2077年上线的《罗德岛吹毛》第一期!是的,在无数次“新建文件夹”之后,我们这个注定伟大的节目终于上线
...
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
ECCV投稿结束一个月了,之前一个研究周期点了一下新的技能点,就是怎么写PyTorch的C++ Extension。网上的教程多是旧体系的写法,我试着摸索了一下新版本该怎么写,现在整理一下留个备份。
这个姓哇的别看24小时高强度微博值班,可是看起来啥也不会啊。你说是摄影博主吧,一年也没正经端过几十小时的相机;你说是美食博主吧,也没正经天天分享美食制作教程;你说是游戏博主吧,他也没拿出什么优秀的比赛成绩……
仔细一想,这9102年确实挺不好看的,不过想来想去,还是想留下一点文字,至少在未来的某一天,能够借助这些文字回忆起这一年都做过啥。
唉,距离上次正经写文章已经有整整四年的时间了,现在果然不会讲故事了,只好用片段的方式来记述旅行中的每一站和每一点感受。
某年月日,某群。
“你群有没有去霓虹玩一周或者一周多的?想去看看军舰还有C96顺带圣地巡礼一把……”我以往的旅行基本上是伴随着比赛或者会议进行的,像六月CP24参会这样目的性很强的旅行少之又少。这一次,我想碰碰运气看看能否找到同伴。
没有回复,在此之后的微博寻找同行者计划也以失败告终。与此同时,实习工作突然忙碌起来,这个旅行计划也就逐渐被搁置掉了。
本以为自己会错过本科期间最后一场旅行,结果直到距离C96还有20天时,老板突然给假,虽然时间不长,但是足够覆盖C96,也许,这是开启第一次海外之行的好机会。于是,一段匆忙开始准备的行程终于准备展开。那么,这个哇凉月能不能回收掉上面的flag呢?
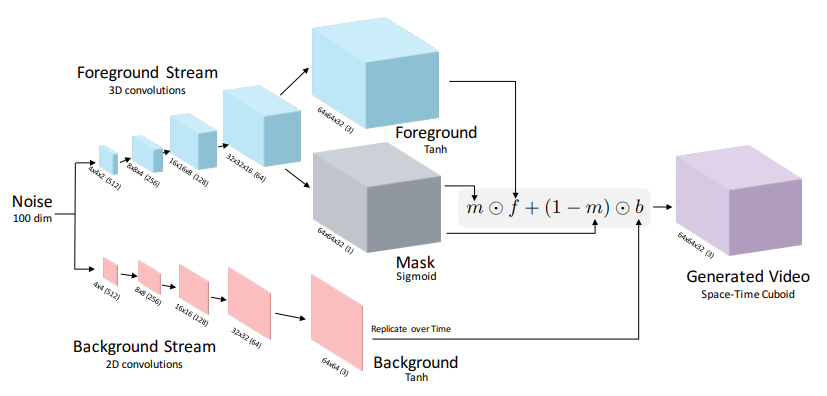
这篇文章中了NIPS 2016,是第一篇正儿八经做Video Generation from scratch的工作。
正如你们所看到的,我的blog因为一些原因重建了,这次的blog本体一定会好好做备份的,绝对不会再丢数据了(评论除外,这个我暂时没法保证)
当然,以前关注m1saka.moe的友人会注意到,以前那个站叫PalePort,现在改名了。想来想去,新名字对于概括blog中会讲到的内容这一行为更能make sense一些吧。