这篇文章中了NIPS 2016,是第一篇正儿八经做Video Generation from scratch的工作。
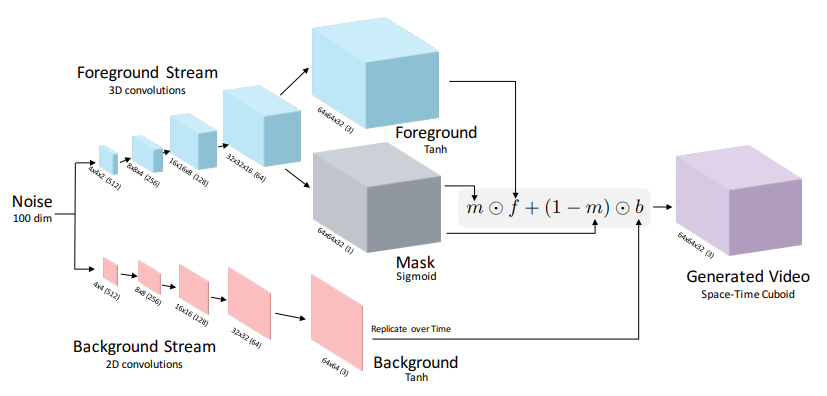
我们来概述一下思路。由于本文是要完成随机生成整段视频的任务,所以输入自然是一段latent variable,或者说,一个特定维度的随机噪声。当然也可以加入condition从而指导生成特定类别的视频,但这是后话。在这里,作者做了个假设,假定对于一段视频,背景部分始终为静态,所以只需要做图像生成就可以;对于前景部分,由于都是动态物体,所以需要生成一个连续的sequence。
基于这个假设,作者将Video Generation这个任务中的Generator解耦成了两个部分:第一个部分是背景的生成,就是一个传统的Image Generation;第二个是前景生成,考虑到要引入temporal上的连续性,作者采用了3D Convolution。当然,这里还是有个问题,那就是即使是生成前景也不能直接保证只用卷积就能生成出恰好只有精确物体的区域,所以前景分支还是需要额外学一个0-1 mask,用这个东西来完成一个前景-背景分割问题。生成完以上这些之后,可以利用mask圈出需要的前景,以类似贴图的形式贴到背景上。
对于Discriminator,作者其实并没有刻意去设计,只是用了简单的3D Convolution构造了一个二分类网络。其实说是二分类网络也不太确切,WGAN的Discriminator毕竟最终的output是一个具体的得分/向量,算距离用的。
其他的部分和标准的GAN差不多。当然,作为baseline,作者也只是验证了这一思路是可以完成生成整段视频的任务的,图像质量和语义层级的质量提升,并没有着重考虑,因此有很大的改进空间。
(深夜强行赶了一份出来,就简单写写结束好了)